AI boti mají HTTP 200. To ale ještě neznamená, že opravdu vidí váš obsah

Kdo dnes řeší SEO a viditelnost značky v AI odpovědích, ten by se neměl dívat jen na Googlebot. Stále důležitější je i to, jak váš web vidí boti OpenAI, Anthropic nebo Perplexity. Právě proto dává smysl podobný test dostupnosti AI crawlerů, který umí ověřit, jak se k webu dostanou jednotliví boti a zda jim v cestě nestojí robots.txt, firewall, CDN nebo jiné technické vrstvy.
Na první pohled se může zdát, že když web vrací HTTP 200, je vše v pořádku. Jenže v praxi to tak být nemusí. Stavový kód 200 pouze říká, že server nějak odpověděli úspěšně. Už ale neříká, jaký obsah konkrétní crawler skutečně dostal, zda je pro něj použitelný a jestli se jedná o stejnou verzi stránky, jakou vidí běžný návštěvník.
Vhodný je například nástroj AI Bot Analyzer, který umí ověřit, jak se k webu dostanou jednotliví boti a zda jim v cestě nestojí robots.txt, firewall, CDN nebo jiné technické vrstvy.
Co ukazuje přiložený výsledek
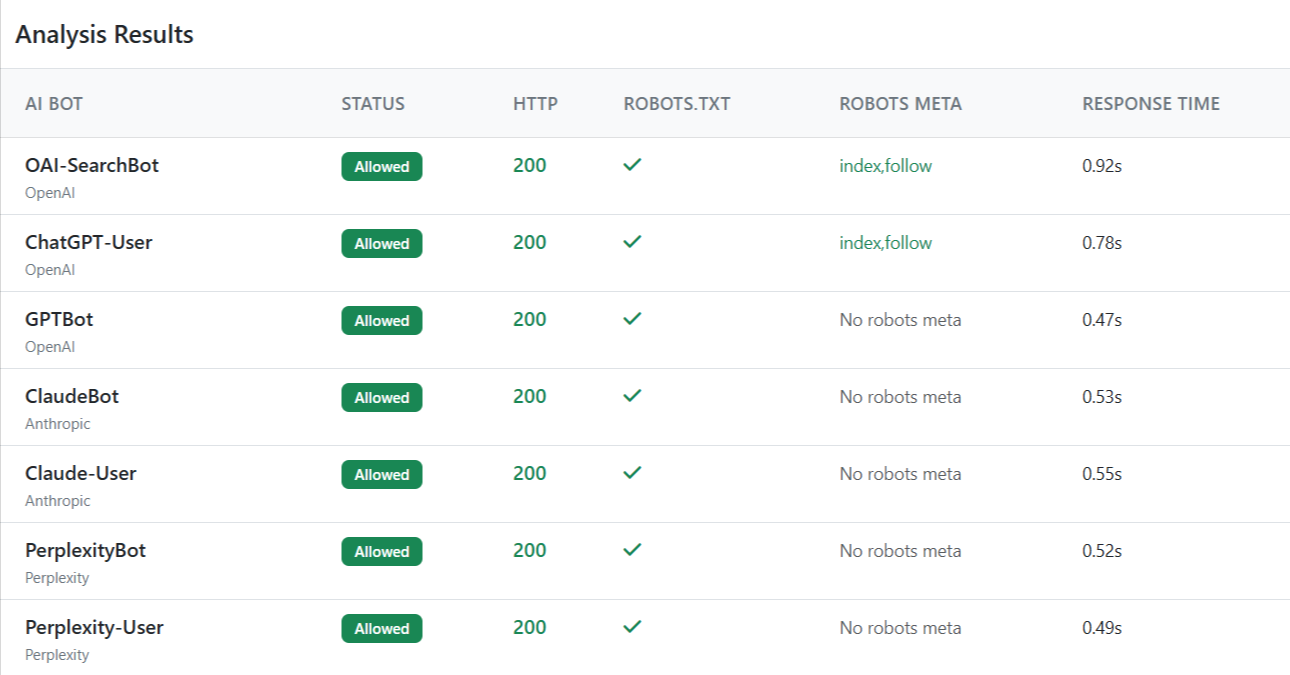
Na přiloženém screenshotu vidím pro testované AI boty velmi pozitivní výsledek. Všichni mají stav Allowed, všichni dostávají HTTP 200, u všech je splněna kontrola robots.txt a odezva serveru je poměrně rychlá. Rozdíl je pouze ve sloupci Robots Meta, kde se u některých botů zobrazuje index,follow a u jiných No robots meta.
Takový výstup může vypadat jednoduše: vše je povoleno, web funguje a hotovo. Jenže právě sloupec Robots Meta si zaslouží přesnější výklad, protože se kolem něj často dělají chybné závěry.
„No robots meta“ samo o sobě neznamená problém
Je důležité říct to přesně: hodnota „No robots meta“ sama o sobě neznamená, že je obsah pro crawler nedostupný. Ve skutečnosti to často jen znamená, že stránka neobsahuje explicitně vložený meta tag typu index,follow. To ale vůbec nemusí vadit. Pokud žádná restriktivní instrukce na stránce není, jde běžně o standardní stav.
Naopak by bylo chybou číst výsledek tak, že boti s hodnotou No robots meta obsah nevidí. Z přiloženého screenshotu to neplyne. Plyne z něj pouze to, že nástroj na dané stránce nenašel explicitně nadefinovanou meta robots instrukci.
Kdy může mít crawler HTTP 200 a přesto je obsah fakticky nedostupný
To nejdůležitější je jinde. V praxi existuje řada situací, kdy web vrací HTTP 200, ale konkrétní AI crawler přesto nedostane reálně použitelný obsah.
1. Server vrátí úspěšnou odpověď, ale ne skutečný obsah stránky
Web může botovi poslat jen prázdnou šablonu, skeleton screen, načítací stav nebo technickou mezistránku. Navenek tedy vše vypadá v pořádku, protože odpověď je 200, ale crawler nedostane text, produktové informace ani hlavní obsah článku.
To je časté hlavně u webů, které hodně spoléhají na JavaScript nebo na dynamické dotahování obsahu až po načtení stránky v prohlížeči.
2. Různí boti mohou dostávat různé verze stránky
Další riziko je v tom, že server nebo bezpečnostní vrstva reagují odlišně podle user-agentu. Běžný uživatel v prohlížeči vidí plnohodnotný obsah, ale konkrétní AI bot dostane zjednodušenou verzi, omezený výpis, jinou jazykovou variantu nebo jen ochrannou stránku.
Výsledek je stále HTTP 200, ale stránka je pro daného crawlera fakticky nepoužitelná. Z pohledu SEO i GEO je to zásadní rozdíl.
3. Obsah se zobrazí až po další interakci
Některé weby načítají hlavní obsah až po kliknutí, scrollu, odsouhlasení cookie lišty nebo po dodatečném API requestu. Pro člověka v běžném prohlížeči to nemusí být problém. Pro crawler ale ano, protože ten si často odnese jen výchozí HTML bez skutečného obsahu.
I tady tedy může být stav 200, ale informační hodnota stránky pro bota je minimální.
4. Meta robots nic neblokuje, ale blokace může být jinde
Meta robots je jen jedna z vrstev. Omezení může být řešeno i jinak, například přes HTTP hlavičky, bezpečnostní pravidla na CDN, WAF ochranu, geoblokaci nebo rate limiting. Bot tedy projde přes robots.txt a dostane 200, ale stejně je odříznut od plného obsahu.
V takové situaci sloupec No robots meta vůbec neukazuje skutečný problém. Ten je schovaný jinde v infrastruktuře.
5. Crawler dostane jiný obsah než návštěvník
Tohle je jedna z nejzrádnějších variant. Nejde o klasickou blokaci, ale o fakt, že bot sice přístup má, jenže vidí jiný HTML výstup než člověk. Může jít o jazykové přesměrování, jinou šablonu, prázdný obsahový blok nebo třeba stránku závislou na cookies a session.
Test pak ukáže 200 a povolený přístup, ale z hlediska citovatelnosti v AI odpovědích nebo využitelnosti pro crawling je situace slabší, než se na první pohled zdá.
Jak číst konkrétně tento screenshot
Když budu vycházet přímo z přiloženého obrázku, základní technická přístupnost vypadá dobře. Testované boti nejsou blokováni přes robots.txt, server na jejich požadavky odpovídá a nevrací chybu.
Současně ale není správné zaměňovat No robots meta za nedostupnost obsahu. Tento údaj sám o sobě jen říká, že nástroj nalezl explicitní meta robots instrukci. Neříká automaticky, že bot obsah nevidí.
Skutečný problém by nastal až tehdy, kdyby konkrétní crawler sice dostal HTTP 200, ale přitom by:
- dostal prázdné nebo ořezané HTML,
- narazil na ochrannou mezistránku,
- obdržel jinou verzi stránky podle user-agentu,
- nedostal hlavní obsah bez JavaScriptu,
- nebo viděl stránku jinak než běžný návštěvník.
Proč je to důležité pro SEO i GEO
V klasickém SEO jsme si zvykli kontrolovat indexaci hlavně přes Googlebot. Dnes ale roste význam i toho, zda váš obsah dokážou načíst a použít systémy, které stojí za odpověďmi v ChatGPT, Claude nebo Perplexity. Nestačí tedy jen říct, že web vrací 200 a není zakázaný v robots.txt.
Je potřeba řešit i to, zda AI crawler dostane plnohodnotný, čitelný a citovatelný obsah. A právě zde se často ukáže, že základní technický test je jen první krok, nikoli finální odpověď.
Co doporučuji kontrolovat v praxi
Pokud chcete mít jistotu, že je váš web skutečně připravený pro AI crawlery, vyplatí se kontrolovat více vrstev najednou. Nestačí jen stavový kód a robots.txt.
- Porovnat skutečný HTML výstup pro běžný browser a pro konkrétní AI boty.
- Prověřit, zda server nebo CDN neposílají odlišnou verzi stránky podle user-agentu.
- Zkontrolovat, zda hlavní obsah existuje už v prvotním HTML.
- Ověřit, že crawler nenaráží na cookie wall, geo variantu nebo ochrannou challenge stránku.
- Prověřit i další vrstvy omezení mimo samotný meta robots tag.
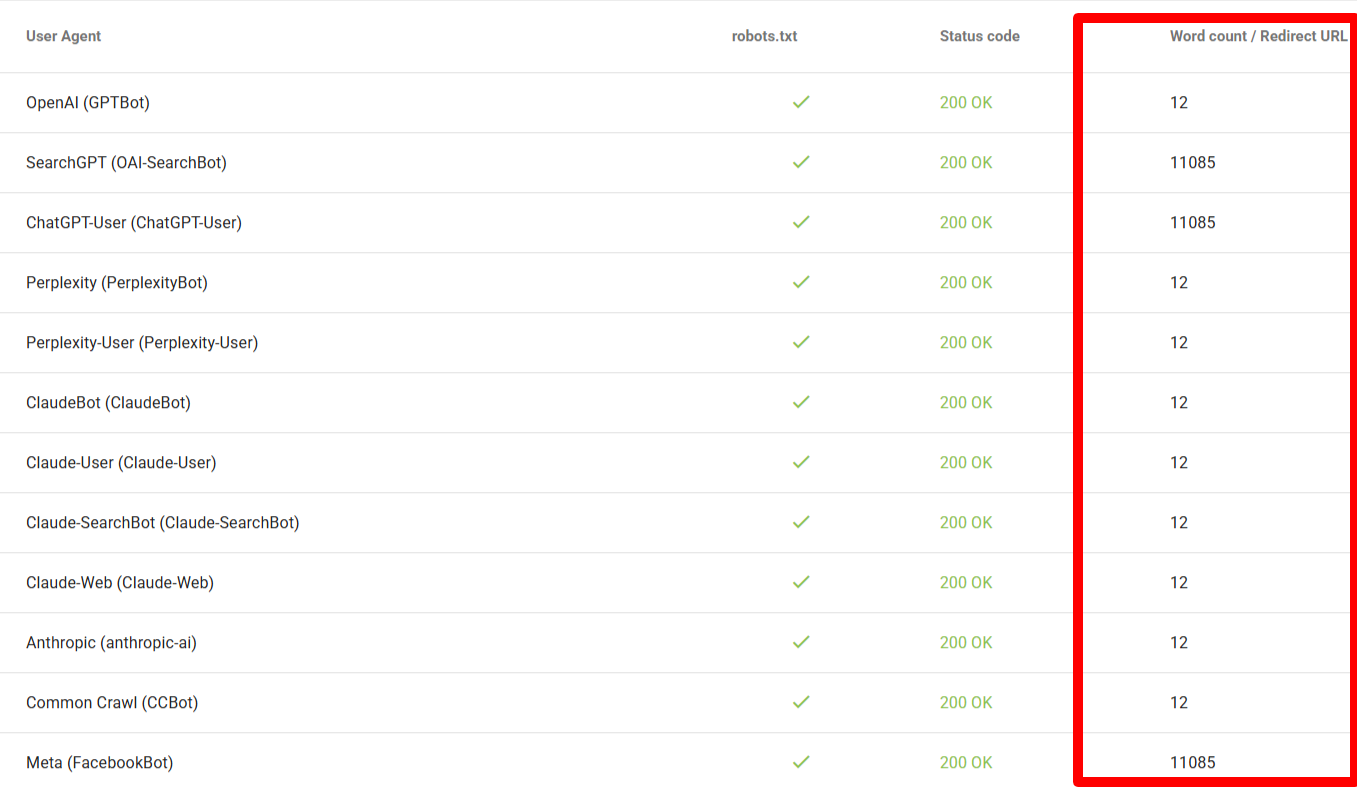
Kromě zkontrolování samotného přístupu je dobré si vždy prakticky překontrolovat, kolik slov konkrétní AI bot z vaší stránky skutečně získá. Právě zde se může rovnou ukázat, že místo plnohodnotného článku dostal crawler například jen prázdnou hlavičku. K rychlému ověření doporučuji skvělý nástroj AI Bot Access Validator od TechnicalSEO, který vám v jednoduché tabulce názorně ukáže metriku Word count pro jednotlivé boty.
Shrnutí
HTTP 200 není automaticky důkaz, že AI bot skutečně vidí váš obsah tak, jak potřebujete. Je to pouze informace, že server nějak úspěšně odpověděl. Stejně tak No robots meta neznamená samo o sobě problém. Jen říká, že stránka neposílá explicitní meta robots instrukci.
Skutečná diagnostika začíná až ve chvíli, kdy řešíte, jaký obsah konkrétní crawler opravdu dostal, zda je plný, čitelný a použitelný pro další zpracování. A právě na tom se dnes láme nejen technické SEO, ale i budoucí viditelnost webu v AI odpovědích.
Líbil se vám článek?
Přidejte si můj blog mezi preferované zdroje na Googlu a nezmeškejte žádné novinky ze světa SEO.
Přidat do preferovaných zdrojů na Googlu